
Understanding the PostgreSQL Group By Clause in Detail
The PostgreSQL Group By clause is one of the PostgreSQL and the relational database system’s key features. This command is responsible for the creation of groups of rows from one or more column in a table. The possibility of using PostgreSQL Group By clause means that users are able to apply aggregate functions to every group which can be a very good tool to summarize and analyze large datasets effectively.
In fact, the use of PostgreSQL Group By clause is crucial to its SQL queries where different users can do various kinds of tasks including counting, averaging, summing, finding the maximum and minimum values among data groups BUT NO WHERE. So, when people rely on PostgreSQL Group By Clause, they acquire new insights from their data and develop their skills to work with complex information effectively.
When dealing with complex queries, the PostgreSQL Group By clause is the main driving force as far as data analysis and reports are concerned. It allows users to categorize data according to various columns and further, calculations as to how many, the total amount, the average value, the highest, and the lowest numbers are done by these groups, in turn, creating highly summarized results. Whether one is dealing with sales data, customer records, or employee information, the PostgreSQL Group By clause helps enable clearer data visualization and aids in more efficient decision-making.
This guide deals with the PostgreSQL Group By clause using SQL queries from a closer perspective. It looks closely at the basic syntax and the advanced usage of the PostgreSQL Group By clause. Moreover, we will look at the optimization techniques and performance factors that play a role in the PostgreSQL Group By clause itself, and how smooth it is in working with large datasets. Properly understanding the PostgreSQL Group By clause through the acquisition of developers’ and analysts’ knowledge to write sustainable and effective queries consequently, the whole performance of the database will highly be boosted.
Application of the PostgreSQL Group By clause allows users to dive deeper into their data and derive the most relevant outcomes. Whether moving data into groupings, performing complex aggregations, or generating summary reports, the PostgreSQL Group By clause is one of the most important and powerful tools in SQL. It helps users to pull in their raw data and grind further into the data in a way that is both understandable and adoptable, which is why it is so important in working with large datasets.
1. What is the PostgreSQL GROUP BY Clause?
- In PostgreSQL, the GROUP BY clause is used to separate rows that have one or more columns in common to their values.
- Aggregate functions like COUNT(), SUM(), AVG(), MAX(), and MIN() are then implemented on these groups to get the summarized results.
- The general group by clause syntax is as follows:
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
WHERE condition
GROUP BY column1, column2;
- column1, column2: These are the columns by which the data is grouped.
- AGGREGATE_FUNCTION(column3): This is an example of an aggregate function (e.g., COUNT(), SUM()) made to apply to a column.
- table_name: The name of the table from which data is retrieved.
- condition: An optional filtering condition specified with the WHERE clause.
2. Basic Syntax and Examples
The method of the GROUP BY clause can be demonstrated in simple exercises at first instance.
Example 1: Grouping by a Single Column
- Pretend you have a table wherein sales are logged with columns being product_id, amount, and sale_date.
- To figure out the total sales by products, first, you a GROUP BY clause will be grouped by the product_id column and then a SUM() function will be used to calculate the total sales.
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;
- This query groups the sales records by product_id and calculates the sum of the amount for each group.

Example 2: Grouping by Multiple Columns
- At times, you may need to group the data through multiple fields.
- For one, this can be the case if you want to count the whole amount of sales for each product in each year.
- You can step through both product_id and year of the sale by this.
SELECT product_id, EXTRACT(YEAR FROM sale_date) AS sale_year, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id, sale_year;
- This query groups sales information from both of the above mentioned columns, i.e. the product_id and sale_year (from sale_date), and then calculates the total sales for each group.
3. Aggregate Functions in PostgreSQL
- The GROUP BY clause is really powerful when you pair it with an aggregate function.
- The aggregate functions are a combination of actions such as calculating the sums of values or counting the number of items in a set or grouping.
- Our database, PostgreSQL, endows inbuilt means for the several types of aggregate functions:
COUNT()
- The COUNT() function is used for counting the rows under a group.
- Example:
SELECT product_id, COUNT(*) AS number_of_sales
FROM sales
GROUP BY product_id;
- This query is able to get the total of sales for every product respectively.
SUM()
- The SUM() function finds the grand total of a numeric column in each group.
- Example:
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;
- The above mentioned query determines product-wise sales.It provides the sum of the total sales for each product.
AVG()
- The AVG() function calculates the average value of a numeric column for each group.
- Example:
SELECT product_id, AVG(amount) AS average_sale
FROM sales
GROUP BY product_id;
- This query finds out the average money made by each product on sales.
MAX() and MIN()
- The MAX() and MIN() functions return the maximum and minimum values for a numeric column in each group.
- Example:
SELECT product_id, MAX(amount) AS highest_sale, MIN(amount) AS lowest_sale
FROM sales
GROUP BY product_id;
- This query calculates the highest and lowest sales amounts for each product.
4. Using the HAVING Clause
- The WHERE clause subjects the information to conditions before executing the GROUP BY clause, while the HAVING clause makes groups distinct after the GROUP BY clause is applied.
- The HAVING clause is the working item that close in on the data that is aggregated.
Example 1: Using HAVING to Filter Groups
- Should you be searching for the goods, with sales greater than 1000, then you would need a HAVING clause:
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id
HAVING SUM(amount) > 1000;
- In this query, the HAVING clause acts as a filter and allows only those groups where the total sales are superior to 1000 to pass on after the GROUP BY step.
Example 2: Using HAVING with Multiple Conditions
- You can also combine multiple conditions with the HAVING clause.
- For instance, you may want to find products with total sales greater than 1000 and at least 50 sales transactions:
SELECT product_id, COUNT(*) AS number_of_sales, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id
HAVING COUNT(*) > 50 AND SUM(amount) > 1000;
- This query filters the products based on both the number of sales and the total sales amount.
5. Handling NULL Values in GROUP BY
- NULL values that are not used by the GROUP BY clause are handled differently in PostgreSQL.
- All of these are grouped together as a single group by design.
- This approach is employed in the large majority of SQL databases.
- For example:
SELECT product_id, COUNT(*)
FROM sales
GROUP BY product_id;
- When there is any record with a NULL value in the product_id column, they will be added to the NULL value group.
6. Performance Considerations for GROUP BY
- GROUP BY clause is one of the options that can have query’s performance affected if we use it with large datasets.
- These are the optimization methods you can apply to improve the performance of your queries:
6.1. Indexing
- To enhance GROUP BY queries, the best practice is to index the columns that are required for grouping the data.
- For instance, you can improve the speed in which the request load is handled by creating an index with the product_id column if the product_id column is often the column used in the GROUP BY clause.
CREATE INDEX idx_product_id ON sales(product_id);
- Indexing allows PostgreSQL to directly identify the rows that belong to each group, thereby eliminating the sorting of the data. As a result, it can be seen that the sorting of the data is done in a shorter time frame without any slowdown.
6.2. Using LIMIT with GROUP BY
- Suppose you want to deal with a specific set of data from the groups and just select the top 5 products the customer buys, for example, you can use the LIMIT clause to control the number of rows returned.
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 5;
- Such a query restricts the result set to only the top 5 products with the highest total sales.
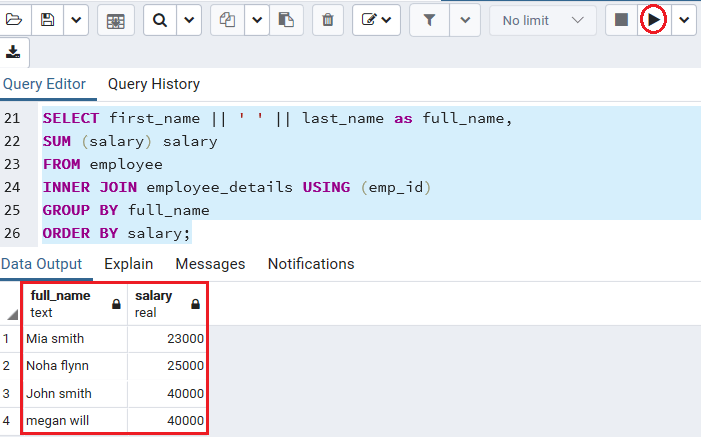
6.3. Avoiding Complex Expressions
- When grouping by complex expressions such as calculated fields or functions, it is necessary to keep performance and complexity in mind.
- The query can be slowed down by grouping on complex expressions as PostgreSQL has to calculate the expression for each row before it can group it.
- For instance, rather than grouping by a complicated expression like EXTRACT(YEAR FROM sale_date), at first, you can sequentially calculate the expression in a subquery:
SELECT sale_year, SUM(amount) AS total_sales
FROM (
SELECT EXTRACT(YEAR FROM sale_date) AS sale_year, amount
FROM sales
) AS subquery
GROUP BY sale_year;
- This quite proves to be of great help where the data might be grouped in a more logical and efficient manner by PostgreSQL.
7. Advanced Usage of GROUP BY
7.1. GROUPING SETS
- There are advanced grouping techniques supported in PostgreSQL, such as GROUPING SETS, which makes you capable of doing many groupings in a single query.
- An example is given below:
SELECT product_id, EXTRACT(YEAR FROM sale_date) AS sale_year, SUM(amount) AS total_sales
FROM sales
GROUP BY GROUPING SETS ((product_id, sale_year), (product_id), (sale_year));
- With this query, the data gets grouped by both the product_id and the sale_year and by the product_id and the sale_year alone.
7.2. CUBE and ROLLUP
- CUBE and ROLLUP are special types of SQL expressions that are used to summarise the data into cohesive level of data for your business requirements.
- CUBE: Produces all possible subtotals for all the grouping columns.
- Example:
SELECT product_id, EXTRACT(YEAR FROM sale_date) AS sale_year, SUM(amount) AS total_sales
FROM sales
GROUP BY CUBE (product_id, sale_year);
- ROLLUP: Produces partial totals over the groups, beginning with the most detailed level.
- Example:
SELECT product_id, EXTRACT(YEAR FROM sale_date) AS sale_year, SUM(amount) AS total_sales
FROM sales
GROUP BY ROLLUP (product_id, sale_year);
- Both CUBE and ROLLUP are useful tools for generating summary reports with totals and subtotals.