
Data Models: Understanding the Types of Data Models
In a database management system (DBMS), Almighty has vast dominion over the data, specifying the arrangement, presentation, and consistency. In order to manage existing information, data models are used. A specific data model is in charge of defining the style, connections, limits, and actions of the data.
These models provide the way to understand the storage of the data of a database and through logical means. By allowing the system to handle messages in a proper manner, they help users to manage, retrieve and manipulate the data quickly. Data models are also an abstraction of the complex underlying data storage issues; it makes it easier for the developers and the users to play with databases.
Types of Data Models :
There are different types of data models at different levels of abstraction used in various operating systems and database brands. Each of the data models represents the first step in conceptualization and data organization and therefore a part of the process of data model requirement and user satisfaction. In this paper, we will investigate four major types of data models that are the core techniques used in database modeling of the present time, which include the Relational Data Model, the Entity-Relationship Model, the Object-Based Data Model, and the Semistructured Data Model.
The types of data models are designed in such a way that they cater to the different demands and requirements of a system, be they simplicity, flexibility or handling of complex data relationships. Say, for example, the Relational Data Model that arranges data into tables and relationships, as a result, becomes one of the most popular types of data models in commercial data processing. On the other hand, the Entity-Relationship Model offers a high-level conceptual approach for database design and is especially helpful during the initial stages of structuring a system.
The true importance of the other type of data model – Object Sorted Data ElementType is the need to implement the objected-based programming algorithms. This does not mean that the data is accessible from any place but, it can be transferred between devices. The semistructured model is abstract and not very specific or regular.
The Object-Based Data Model and other types of data models, incorporate principles of object-oriented programming, enabling the data to be displayed in the form of objects that consist of both the set of its attributes and the way it behaves. The last model, namely, the Semistructured Data Model, refers to a data model whose structure is quite flexible and therefore is suitable for the types of data models that are not related to traditional relational schemas as would be the situation when the given data is in the XML format.
Eventually, whether your database is going to be a leading model or something that needs upgrading, the kind of data model that you choose will determine these factors. One good thing about each type of data model is that they are uniquely better than the rest, and the decision for use depends on variables that include but are not limited to the dimension of data, user side necessities, and what you expect to get from the metrics.
The growth of the database sector will surely not stop here. Subsequently to the fact that the database technology world is in a state of constant change, new types of data models can be identified, thus providing the developer with a larger number of options to use for building database systems. So therefore, a very deep knowledge about these types of data models is required to control this complicated amount of modern database management.
1) Relational Data Model
- The Relational Data Model, the one developed by Edgar F. Codd in 1969, is the probably the widely used and the well-known model in the modern database systems.
- It structures the data in tables (or relations) for what each table contains rows (also known as tuples) and columns (also known as attributes).
- This model is also based on the idea that all the data and databases can be converted to the table concept and thus is a simple yet a powerful data storage and querying approach.
Key Characteristics:
- Tables (Relations): Data is kept in tables, which are built up of rows (records) and columns (attributes).
- Primary Keys: A primary key for every record in each table is clubbed with it that must be unique. This key defines the uniqueness of a row.
- Foreign Keys: Joining (linking) of tables is achieved by means of foreign keys. A foreign key in one table refers to the primary key in another table, hence forming a connection between them.
- Normalization: The relational model is mainly concerned with the process of normalization. It involves organizing data in such a way as to reduce redundancy and dependency.
Example:
As an example suppose a university database case, where there are two tables: Students and Courses.
- Students Table:
| StudentId | Name | Major | Enrollment Year |
| 1 | John Doe | Computer Science | 2022 |
| 2 | Jane Smith | Mathematics | 2021 |
- Courses Table:
| CourseId | CourseName | Credits |
| 101 | Introduction to Computer Science | 3 |
| 102 | Calculus I | 4 |
To interconnect the given tables, the third table, StudentCourses, the foreign keys of which establish fealties for the others:
- StudentCourses Table:
| StudentId | CourseId |
| 1 | 101 |
| 2 | 102 |
In this instance, the StudentCourse table relates the students to the classes they are taking. In this case, the primary key for StudentID is in the StudentCourses table which is linked to the Students table, and the foreign key for CourseID is in the StudentCourses table linked to the Course table.
Relational model is considered to be one of the most favored DBMS (Data Base Management Systems) as it is intuitive, flexible and is compatible with the SQL (Structured Query Language) for querying and database management. It is due to the model, which is not only for proper data retrieval, saving, and other activities, is efficient but it also minimizes the data redundancy.
2) Entity-Relationship (ER) Data Model
- ER Data Model is a high-level conceptual framework that serves as a basis for the description of database schema.
- Back in 1978, Peter Chen was the one who first introduced the Entity-Relationship (ER) Data Model and said that it is a graphic which represents data and its connections.
- The users of this pattern are the developers who use this design at the time of the database design to enable the database users to understand the connections between different data entities.
Key Characteristics:
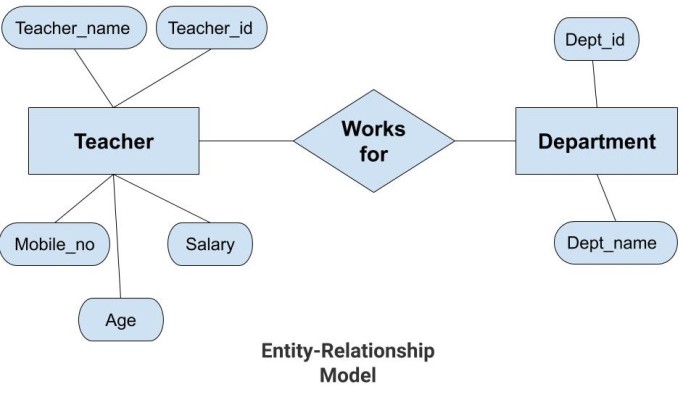
- Entities: Entities are objects or concepts that have data attributes associated with them. As an example, a Student entity might have attributes like StudentID, Name, and Enrollment Year.
- Attributes: Attributes are properties that describe an entity. To exemplify, a Course entity may possess attributes such as CourseID, CourseName, and Credits.
- Relationships: A relationship stands for the association between two or more entities. For instance, a Student is related to a Course through the relationship Enrolls In.
- Cardinality: Cardinality is the term, which tells us how many instances of one entity can be associated with the other entity. One student may enroll in more than one course, but a course may have more than one student.
- Primary Keys: Mostly, primary keys are used to uniquely identify entities, but in the relational model they can be almost anything that is quick and unique to find such as StudentID or CourseID.
Example:
If we wanted to create a university base on the idea of ER, we would have to look into the entities and their connections:
- Entities: Student, Course, and Instructor.
- Attributes: These entities may have attributes such as StudentID, Name, Major and Enrollment Year. A Course might be defined as a CourseID, a CourseName, and the credits granted upon completion. An Instructor entity can include the following attributes: the InstructorID, the Name, and the Department.
- Relationships: A Student Enrolls in a Course, and the Instructor Teaches a Course.
In this ER diagram, the entities are in the form of rectangles while the relationships are in the form of diamonds that are connected to the relevant entities.
Thirdly, the ER model emerges as a widely known method in the early stage of database design as it can give a very clear and intuitive perspective on the interconnections within different data structures.
3) Object-Based Data Model
- The Object-Based Data Model is an upgrade of the ER Model that includes the principles of the object-oriented approach like encapsulation, inheritance, and polymorphism.
- The information is represented by objects having both data and behavior.
- The behavior is being managed by behaviors (methods) The de rigueur model for the description of data in object-oriented databases got its start in the 1980s and is still current when the relational model becomes insufficient to work with complex data types.
Key Characteristics:
- Objects: Data is stored as objects. Every object mentioned is an example of a class which has both the data and the methods (functions).
- Encapsulation: Each object is an instance of a class, and it is packaged together with them, meaning that its data and methods are in one solid entity. The object is the only one which is indirectly modified via its methods.
- Inheritance: The classes permit the properties and the behaviors to be taken as if a class owns them from another, the styles of the code can thus be closely related and code reuse realized.
- Polymorphism: Objects can be cast in different ways, the methods are then capable of doing different things in accordance with the object’s type.
Example:
Let’s look at a university database that holds student, course, and instructor as entities. In the object-based model, these entities are objectified:
- Student Class:
- Attributes: StudentID, Name
- MajorMethods: EnrollInCourse(), DropCourse()
- Course Class:
- Attributes: CourseID, CourseName
- CreditsMethods: AddStudent(), RemoveStudent()
- Instructor Class:
- Attributes: InstructorID, Name
- DepartmentMethods: AssignGrade(), TeachCourse()
The object-based data model is a better choice when it comes to dealing with the representation of complex and real systems where entities are behavior-driven and data-directed. It especially benefits those applications that require sophisticated data modeling, like multimedia databases, CAD/CAM systems and geographic information systems (GIS).
4) Semistructured Data Model
- Asemistructured data model, being a data type that falls in the middle of the structured data and the unstructured data, is a kind of model.
- Unlike the relational or object-based models, semistructured data doesn’t have a fixed schema. Instead, it allows for flexibility in data representation.
- The model is specifically useful for data that does not map nicely into rows and columns or for data that is likely to change over time.
- The Extensible Markup Language (XML) is one of the most widely used formats to represent semistructured data.
Key Characteristics:
- Flexible Schema: Semistructured data does not require a predefined schema. Each record may have different attributes.
- Tags and Hierarchy: Data is often represented in a hierarchical structure using tags (e.g., XML tags). This allows for easy nesting of data.
- Data Types: Semistructured data can represent various data types, including text, numbers, and multimedia content.
Example:
An example of semistructured data could be an XML document representing an employee’s information:
<Employee>
<EmployeeID>123</EmployeeID>
<Name>John Doe</Name>
<Department>HR</Department>
<Skills>
<Skill>Communication</Skill>
<Skill>Negotiation</Skill>
</Skills>
</Employee>
In the case of the Employee entity, there are multiple attributes like EmployeeID, Name, and Department, but it is also a nested list of Skills. This flexibility enables the system to handle different types of data in the same structure, thus making it useful for applications that are of diverse or changing datasets.